## Antes de mais nada
[Uma demo!](https://guites.github.io/ai-collage/)
Vamos ver um modelo de IA funcionando.

## Explorando IA no navegador
Por **Guilherme Garcia**

```html
.
├── [2015-2019] Licenciado-em-Física.txt
├── [2019-Presente] Desenvolvedor-de-software.txt
└── [2022-Presente] Entusiasta-de-IA.txt
```
(slide pra eu lembrar de)
- perguntar sobre vocês
- lembrar que eu quero acabar a apresentação em uns 20min
## Mas afinal o que é IA?
Software que assimila padrões...
De linguagem (NLP):

De imagens (Computer vision):

De regras de um sistema (jogos):
## Mas tudo é IA?
Nem toda forma de assimilar padrões é baseada em inteligência artificial
[Por exemplo](https://www.expunctis.com/2019/03/07/Not-so-random.html)
(tentem jogando até 100!)
## Qual a diferença?
Por que dizemos que alguns softwares aprendem?

## Redes Neurais
[Analogia entre neurônios e nodes](https://excalidraw.com/#json=5Ji0N3Ta6pkP2gYR6SEk8,dVbSLzGch9uanUgAlNoF4A)
[Imagem, caso o link acima pare de funcionar](./slide-imgs/nn-exemplo-buts.png)
## Tamanho dos modelos
O modelo usado no início tem cerca de 30 camadas e ~4 milhões de parâmetros.

## O aprendizado da máquina

## Com o que alimentamos os modelos?
[Ver o dataset COCO-2017!](https://cocodataset.org/#explore)
> Nota: na apresentação original, eu carreguei uma fração do dataset no software [FiftyOne](https://docs.voxel51.com/), pra facilitar a exploração dos dados.
## Visão Computacional

## O que o modelo aprende?
Uma vantagem didática da visão computacional:
- podemos traduzir os pesos de cada camada em imagens
(no próximo slide)
No topo, as imagens reconstruidas dos pesos do modelo, e embaixo, fragmentos das imagens utilizadas que mais se aproximam dos valores.


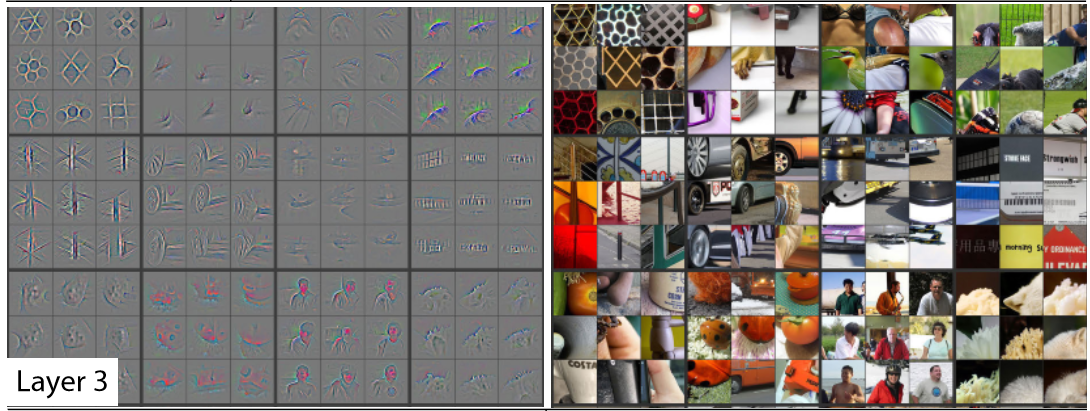

O modelo analisado foi o AlexNet, que possuia apenas 5 camadas
Era um dos melhores ali por 2012
Isso trás problemas de privacidade e também de viés

Mão na massa
[A máquina ensinável](https://teachablemachine.withgoogle.com/)

### Fontes
(que não foram citadas no texto)
- https://developers.google.com/machine-learning/glossary#feature-vector
- https://community.cadence.com/cadence_blogs_8/b/breakfast-bytes/posts/linleyspr22
- https://xkcd.com/2169/
- https://github.com/patrickmetzner/AI_Practice
- https://github.com/fastai/fastbook/blob/master/01_intro.ipynb

